
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1509
ISSN 2229-5518
Text-to-Speech Synthesis for Myanmar Language
Ei Phyu Phyu Soe, eiphyu2soe@gmail.com
Aye Thida, ayethida.royal@gmail.com
Abstract— Text-to-speech (TTS) synthesis for various languages has been discussed in the Natural Language Processing research (NLP) field. In this paper, text-to-speech synthesis for Myanmar language is presented. TTS system can be divided into two key phases such as high-level and low-level synthesis. In high-level synthesis, the input text is converted into such form that the low-level synthesizer can produce the output speech. TTS synthesis for Myanmar language consists of four components such as text analysis, phonetic analysis, prosodic analysis and speech synthesis. Syllable segmentation and number converter for Myanmar language are analyzed in the text analysis. The algorithm for number convertor for Myanmar language is proposed in this paper. In the phonetic analysis, the Myanmar syllable text is converted to phonetic sequence to analyze the best sequence of phonemes of words, numbers and symbols by applying Myanmar phonetic dictionary. In prosodic analysis, some of different Myanmar words pronounce the same pronunciation so the phonetic sequences are analyzed to produce the naturalness of synthetic speech and voice duration by applying Myanmar phonological rules. Myanmar diphone dictionary is constructed for speech synthesis and PSOLA algorithm is proposed in this paper.
Index Terms— Text-to-Speech, Syllable Segmentation, Text Analysis, Phonetic Analysis, Myanmar Phonological Rules, Prosodic Analysis, Speech Synthesis
—————————— ——————————
ext-To-Speech technology gives computers the ability of converting text into audible speech, with the goal of being able to deliver information via voice mes-
sage. It has been utilized to provide easier means of com- munication and to improve accessibility for people with visual impairment to textual information. Two quality cri- teria are proposed for deciding the quality of a TTS synthe- sizer. Intelligibility – it refers to how easily the output can be understood. Naturalness – it refers to how much the output sounds like the speech of a real person. Most of the existing systems have reached a fairly satisfactory level for intelligibility, while significantly less success has been at- tained in producing highly natural speech [1].
The goal of text-to-speech synthesis (TTS) is the automatic conversion of unrestricted natural language sentences in text form to a spoken form that closely resembles the spoken form of the same text by a native speaker of the language. This field of speech research has witnessed significant advances over the past decade with many systems being able to generate a close to natural sounding synthetic speech. Research in the area of speech synthesis has been fueled by the growing importance of many new applications. These include information retrieval services over telephone such as banking services, public an- nouncements at places like train stations and reading out manuscripts for collation. The purpose of this paper is to de- velop Myanmar Text-To-Speech system and to improve the performance of high quality synthesis by applying the di- phone-concatenation speech synthesis.
————————————————
The Myanmar language is the official language of Myan- mar and is more than one thousand years old. Texts in the Myanmar language use the Myanmar script, which is de- scended from the Brahmi script of ancient South India. Other Southeast Asian descendants, known as Brahmic or Indic scripts, include Thai, Khmer and Lao. Myanmar writing is different from other language because its writing is not used white spaces between words or between syllables. Thus, the computer has to determine syllable and word boundaries by means of an algorithm such as finite-state and rule-based. Moreover, a Myanmar syllable can be composed of multiple characters. Syllable segmentation is the process of determining word boundaries in a piece of text.
Myanmar language consists of one or more morphemes that are linked more or less tightly together. Typically, a word consists of a root or stem and zero or more affixes. Words can be combined to form phrases, clauses and sentences. A word consisting of two or more stems joined together is known as a compound word. To process text computationally, words have to be determined first [5].
A Myanmar text is a string of characters without explicit word boundary markup, written in sequence from left to right without regular inter-word spacing, although inter- phrase spacing may sometimes be used. Myanmar charac- ters can be classified into three groups: consonants, medials and vowels. The basic consonants in Myanmar can be mul- tiplied by medials. Syllables or words are formed by conso- nants combining with vowels. However, some syllables can be formed by just consonants, without any vowel. Other characters in the Myanmar script include special characters, numerals, punctuation marks and signs.
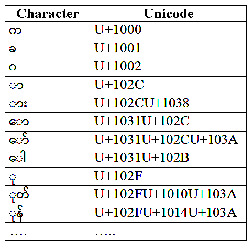
There are 34 basic consonants in the Myanmar script, as displayed in Table.1. They are known as “Byee” in the My-
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1510
ISSN 2229-5518
anmar language [5]. Consonants serve as the base charac- ters of Myanmar words, and are similar in pronunciation to other Southeast Asian scripts such as Thai, Lao and Khmer.
TABLE 1
BASIC CONSONANTS
Vowels are known as “Thara”. Vowels are the basic building blocks of syllable formation in the Myanmar lan- guage, although a syllable or a word can be formed from just consonants, without a vowel as shown in Table 2. Like other languages, multiple vowel characters can exist in a single syllable.
TABLE 2
VOW LES
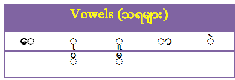
Medials are known as “Byee Twe” in Myanmar. There are 4 basic medials and 6 combined medials in the Myan- mar script as shown in Table 3. The 10 medials can modify the 34 basic consonants to form 340 additional multi- clustered consonants. Therefore, a total of 374 consonants exist in the Myanmar script, although some consonants have the same pronunciation.
TABLE 3
MEDIALS

Special characters for Myanmar language are used as pre- scription noun and conjunctions words between two or more sentences.
TABLE 4
SPECIAL CHARACTERS

Numerals for Myanmar language are known as “Counting
Numbers”. Numerals are the 10 basic digits for counting.
TABLE 5
NUMERALS

TTS system for Arabic languge is implemented which is based on diphone concatenation with Time Domain Pitch Syn- chronous Overlap-Add (TD-PSOLA) modifier synthesizer. TD- PSOLA method is based on the decomposition of the signal into overlapping frames synchronized with the pitch period. Standatrd Arabic has 34 basic phonemes, of which sex vowels and 28 are consonants and the position of the phoneme in the syllables as initial, closing, intervocalic, of suffix The main ob- jective is to preserve the consistency and accuracy of the pitch marks after prosodic modifications of the speech signal and diphone with vowel integrated database adjustment and op- timization [3].
The European Portuguese text-to-speech synthesis used
the two spoken corpora. This is used the unit concatenative synthesis by applying automatic segmentation and aligiment of EUROM. For a rapid implementation and evaluation of a European Portuguese diphone-based concatenative synthesiz- er, the formant synthesizer module of the DIXI system is re- placed by own implementation of a basic TD-PSOLA synthesis module [4].
Standard Malay TTS system is used a rule-based text- to- speech. The proposed system using sinusoidal method and some pre- recorded wave files in generating speech for the system. The use of phone database significantly decreases the amount of computer memory space used, thus making the system very light and embeddable. The overall system was comprised of two phases the Natural Language Processing (NLP) that consisted of the high-level processing of text analy- sis, phonetic analysis, text normalization and morphophone- mic module. The module was designed specially for SM to overcome few problems in defining the rules for SM orthogra- phy system before it can be passed to the DSP module. The second phase is the Digital Signal Processing (DSP) which op- erated on the low-level process of the speech waveform gener- ation. A developed an intelligible and adequately natural sounding formant-based speech synthesis system with a light
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1511
ISSN 2229-5518
and user-friendly Graphical User Interface (GUI) is intro- duced. A Standard Malay Language (SM) phoneme set and an inclusive set of phone database have been constructed careful- ly for this phone-based speech synthesizer. By applying the generative phonology, a comprehensive letter-to-sound (LTS) rules and a pronunciation lexicon have been invented for SMaTTS. As for the evaluation tests, a set of Diagnostic Rhyme Test (DRT) word list was compiled and several experiments have been performed to evaluate the quality of the synthe- sized speech by analyzing the Mean Opinion Score (MOS) obtained. The overall performance of the system as well as the room for improvements was thoroughly discussed [5].
The term 'machine translation' (MT) refers to computerized systems responsible for the production of translations with or without human assistance. It excludes computer-based trans- lation tools which support translators by providing access to on-line dictionaries, remote terminology databanks, transmis- sion and reception of texts, etc. The boundaries between ma- chine-aided human translation (MAHT) and human-aided machine translation (HAMT) are often uncertain and the term computer-aided translation (CAT) can cover both, but the cen- tral core of MT itself is the automation of the full translation process [6].
The source language model includes Part-of-Speech (POS) tagging and finding grammatical relations in Myanmar to English machine translation. The translation model includes phrase extraction, translation by using bilingual Myanmar to English corpus. The translation model also interacts with word secse disambiguation to solve ambiguities when a phrase has with more than one sense. The target languge model includes reording the translated English sentence and smoothing it by reducing grammar errors. The main goal is to construct My- anmar-English mword-aligned parallel corpus. Alignment model is central components of any statical machine transla- tion system. The result corpus will be used in most parts of the Myanmar-English machine translation [7].
Text-to-speech (TTS) is the production of speech by ma- chines, by way of automatic phonetization of the sentence to utter. There are two main modules in the TTS synthesizer, namely Natural Language Processing (NLP) and Digital Sig- nal Processing (DSP). TTS synthesizer produces speech based on the corresponding text input. It has been utilized to provide easier means of communication and to improve accessibility for people with visual impairment to textual information. This language dependent system has been widely developed for various languages with continuous research to improve the quality of the produced speech. Natural language processing module is responsible for conversion of text input into phonet- ic transcription and prosody information. Prosody infor- mation, which includes melody (intonation) and rhythm, is necessary to make the resulting speech sounds natural (not flat/robot-like). The DSP module then transforms the resulting phonetic transcription and prosody information into corre- sponding speech [1].
The text-analysis module of the multilingual Bell Labs TTS system has been developed for Spanish, Italian, Romani- an, French, German, Russian, Mandarin and Japanese lan- guages [2]. They discussed the transducers are constructed using a lexical toolkit that allows declarative descriptions of lexicons, morphological rules, numeral expansion rules, and phonological rules, inter alia.
TTS design for Myanmar language.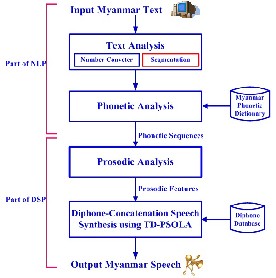
Fig.1. Text-To-Speech Design for Myanmar Langugae
Text analysis takes input in the form of text and outputs a symbolic linguistic representation. The input text is analyzed to segmented Myanmar text like a syllable. Syllable segmen- tation and Number converter are analyzed in this module. Sylla- ble segmentation is the process of identifying syllable boundaries in a text. Segmentation [16] is used in this paper to get the segmented Myanmar syllable. Algorithm for Myanmar number converter is proposed in this paper as shown in figure 2 which can convert the Myanmar number to textual versions. The non standard words are tokens like numbers, which need to be expanded into sequences of Myanmar words before they are pronounced.
Number converter for Myanmar number is a difficult and vital task in TTS synthesis system. Myanmar number is not defined as a number like English because it has a Unicode for
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1512
ISSN 2229-5518
each number. The computer does not easily understand the Myanmar number like English number. So, the system must translate these to machine-language such as Myanmar number
0 to 9 has a Unicode for each. If a number string has 4 words, system will check with their each Unicode. So, number con- verter control a number string with a whole number Unicode according to the counting of number string. The number con- vertor algorithm is divided the input number with whole
Segmented Myanmar Text
Phonetic Analysis
Phoneme Sequence with
Pronunciation
Myanmar Phonetic Dictionary
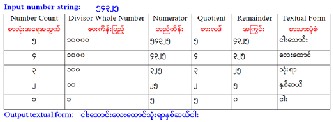
number such as 1000, 100, 10 and it marks the positions of the quotients. But this number converter cannot be transferred the decimal Myanmar number. It can be only changed the sim- pleMyanmar number for million counting. The transforming of Myanmar number to textual form is shown in Figure.3.
Fig. 2. Algorithm for Myanmar Numbers Converter
Fig. 3. Sample of Conversion for Myanmar Digit to Myanmar Text
Phonetic analysis is also called Grapheme-to-Phoneme (G2P) conversion which translates the syllable of Myanmar text to phonetic sequence. It determines the pronunciation of a syllable based on its spelling. It also analyzes the best se- quence of phonemes for words, numbers and symbols and converts into phonetic sequences. The Myanmar phonetic dic- tionary is constructed to generate the phoneme sequence and to pronounce these phonemes.
Fig.4. Overview of Phonetic Analysis
The Myanmar language uses a rather large set of 50 vowel phonemes, including diphthongs, although its 22 to 26 conso- nants are close to average. Some languages, such as French, have no phonemic tone or stress, while several of the Kam-Sui languages have nine tones, and one of the Kru languages, Wobe, has been claimed to have 14, though this is disputed. The most common vowel system consists of the five vowels /i/,
/e/, /a/, /o/, /u/. The most common consonants are /p/, /t/, /k/,
/m/, /n/. Relatively few languages lack any of these, although it
does happen: for example, Arbic lacks /p/, standard Hawaiian
lacks /t/, Mohawk and Tlingit lack /p/ and /m/, Hupa lacks
both /p/ and a simple /k/, colloquial Samoan lacks /t/ and /n/,
while Rotokas and Quileute lack /m/ and /n/ [11]. Table4
shows the phonetic signs of 50 Myanmar vowels to pronounce
the Myanmar words. These 50 phonemes show the basic sym-
bol with four tone levels [8], [10].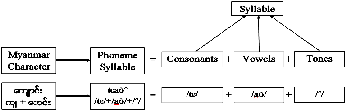
Fig.5. Combination of Phoneme Syllable
Phonology is how speech sounds are organized and affect one another in pronunciation. The combination of consonant phoneme and a vowel phoneme produces a syllable in figure2. The phonetic alphabet is usually divided in two main catego- ries, vowels and consonants. Vowels are always voiced sounds and they are produced with the vocal cords in vibration, while consonants may be either voiced or unvoiced. Vowels have considerably higher amplitude than consonants and they are also more stable and easier to analyze and describe acoustical- ly. Because consonants involve very rapid changes they are more difficult to synthesize properly [9].
The purpose of this paper presents about the diction- ary-based approach for Grapheme-to-Phoneme (GTP) con- version. There are five steps to construct the Myanmar phonetic dictionary:
[1]. Collecting of possibility words
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1513
ISSN 2229-5518
[2]. Separating of consonants and vowels of Myanmar words
[3]. Storing consonants and vowels of phonetic signs
[4]. Recording of Myanmar syllables and
[5]. Segmenting of recorded speech.
In the works of possibility words collection, we find the Myanmar words by looking at Myanmar dictionary book. Myanmar word is collated based on syllables. A Myanmar syllable encoded in Unicode can be broken into 5 parts for collation: <consonant> <medial> <vowel> <final> <tone>. Only the consonant is always present, one or more of the other parts may be empty in any given syllable. In practice the vowel may be displayed before the consonant e.g.
����, but it is encoded as U+1000 (Myanmar letter �)
U+1031U+102CU+103A (Myanmar vowel ���).The result-
ing collation sequence has 5 levels, order of priority: <con-
sonant>, <medial>, <final>, <vowel>, <tone>. Note, that the
final and vowel have been switched from their encoded
order. Each of these parts of the syllable may be composed
of one or more characters. Collation Order read left to right
and then down. The data is presented in the traditional lay-
out of the Myanmar alphabet [6].
The step of separating of consonants and vowels is the
important step in Grapheme-to-Phoneme conversion. Stor-
ing the separated consonants and separated vowels to data-
base decrease the complexity of searching times because the
total compound Myanmar syllables have about near 2000
reduce to the total consonants and vowels have about near
500. To become a Myanmar syllable is combining the possi-
ble compound vowels and consonants. So this system is not
inserting the whole Myanmar syllable because one conso-
nant has near 60 compound vowels. If the system saved 33
consonants x 60 vowels = 1980 syllables to the database, the
searching time and complexity will increase. The advantage
of dictionary-based approach is quick and accurate, but
completely fails if it is given a word which is not in its dic-
tionary. As dictionary size grows, so too does the memory
space requirements of the synthesis system. Table 6 de-
scribes about the separated consonants and vowels of My-
anmar syllables.
There is no problem in inserting the phonetic signs for
consonants but single vowel and compound vowels have a
little problem to match the pronounced of the whole sylla-
ble. In this step, we must insert the data carefully to get the
correct phoneme sequences and pronounced of Myanmar
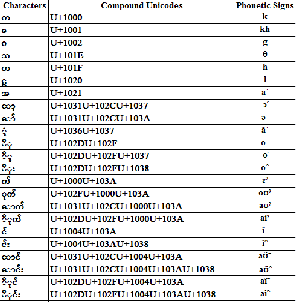
syllables because of producing high quality speech synthe- sis depend on the performance of Grapheme-to-Phoneme conversion step. The phonetic signs are important for My- anmar language analysis and it promotes for the whole sys- tem of Grapheme-to-Phoneme (GTP) conversion [8], [10]. Table 7 shows the phonetic signs for Myanmar characters to produce the phonetic sequences.
TABLE 6
SEPARATED CONSONANTS AND VOW ELS OF MYANMAR WORDS
TABLE 7
PHONETIC SIGNS OF MYANMAR CHARACTERS
After storing the phonetic signs to database, this system stores the segmented recorded speech according to their com- pound Unicodes. Firstly, we record the phone level of the whole syllable. Concerning to constituent phones and syllabic neighboring context, syllable is designed in the form of onset- nucleus-coda. Onset and coda represent single consonants. Nucleus covers short and long vowels, and, short and long diphthongs. The example of grapheme-to-phoneme conver- sion is shown in following table 8.
This data contains fluently read speech recorded by a My- anmar female student thus this reading style is general read- ing style. In syllable level data set, it contains approximately
2000 syllables. In phone-level data set, it contains approxi- mately 4600 phones. The example of grapheme-to-phoneme conversion is shown in below:
TABLE 8
EXAMPLE OF GRAPHEME-TO-PHONEME CONVERSION
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1514
ISSN 2229-5518
![]()
In this step, the phonetic sequences are analyzed to pro- duce the prosodic features by applying the phonological rules. It is the module to analyze duration and intonation such as pitch variation, syllable length to create naturalness of synthet- ic speech. The combination of consonant phoneme and a vowel phoneme produces a syllable. The phonetic alphabet is usually divided in two main categories, vowels and con- sonants. Vowels are always voiced sounds and they are produced with the vocal cords in vibration, while conso- nants may be either voiced or unvoiced. Vowels have con- siderably higher amplitude than consonants and they are also more stable and easier to analyze and describe acousti- cally. Because consonants involve very rapid changes they are more difficult to synthesize properly.
There are five tasks of phonological rules in the process of prosodic analysis for Myanmar Language as shown in over- view of the system design. This system extracts the correct pronunciations by applying the rule-based phonolo- gy.Phonemic forms change to the phonetic forms by applying the phonological rules. Phonological rules link the two levels of underlying and surface of the phoneme. It describes how phonemes are realized as their allophones in the given envi- ronment. Environment in phonology typically refers to the neighboring phonemes.
Input Phonemic Sequence
Rule 1: Vowel Reduction
Rule 2: Changing to “DA” Pronunciation
Rule 3: Inserting Nasal Phoneme Rule 4: Unchanging Pronunciation Rule 5: Changing Pronunciation
Output Phonetic Sequence
Fig.6. System Flow Diagrams for Five Rules
This overview system presents about five phonological rules with the summary processes in Figure6. The process of
Rule 1 is the vowel reduction to reduce the tense vowel with n-gram algorithm. Rule 2 shows about the process of metathe- sis for counting number /tiˀ/ to /də/ pronuncia pronunciation by applying the bigram model. The manner of Rule 3 is un- changing pronunciation phoneme next to the /aˊ/ � syllable until it is an unvoiced phoneme by using forward algorithm. Rule 4 is a difficult process for unvoiced phoneme to voiced phoneme depending on the defined voiced vowel, consonants and asats by applying forward backward algorithm. Rule 5 is an inserting nasal phoneme process to different types of ob- struent by employing digram [12].
Phonological rules can be roughly divided into six types
[12], [14]:
1. Assimilation
2. Dissimilation
3. Reduction
4. Metathesis
5. Insertion and
6. Deletion
Assimilation: When a sound changes one of its features to be more similar to an adjacent sound. This is the kind of rule that occurs in the Myanmar Unvoiced rule described as—the Myanmar syllable “�” becomes voiced or voiceless depending on whether or not the preceding consonant is voiced.
Dissimilation: When a sound changes one of its features to become less similar to an adjacent sound, usually to make the two sounds more distinguishable. This type of rule is often seen among people speaking a language that is not their native language, where the sound contrasts may be dif- ficult.
Reduction: When a sound has high vowel phoneme such as /i,u/ and low vowel phoneme such as /a/ with glottal- ized/ˀ/ or nasal/˜/ tones, high vowel phonemes change to one level of low vowel phonemes such as [ɪ,ʊ] and low vowel phoneme changes to one level of high vowel phoneme such as [ʌ].
Metathesis: When a sound has a Myanmar countable number ‘one’ ��� /tiˀ/, it changes to schwa [də] depending on the next consonant is unvoiced syllable.
Insertion: When an extra sound is added between two others. This also occurs in the Myanmar Nasal rule: when the nasal consonant -m is added to "bilabial obstruent".
Deletion: When a sound, such as a stress less syllable or a weak consonant, is not pronounced; for example, most American English speakers do not pronounce the [d] in "handbag". There is no syllable or a weak consonant in My- anmar language.
In this paper, we proposed the phonological rules based on five types for Myanmar language pronunciations except deletion.
The aim of speech synthesis is to be able to take a word se- quence and produce “human-like” speech. Linguistic analysis stage maps the input text into a standard form and determines
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1515
ISSN 2229-5518
the structure of the input, and finally decides how to pro- nounce it. Synthesis stage converts the symbolic representa- tion of what to say into an actual speech waveform [13].
Speech communication relies not only on audition, but al- so on visual information. Facial movements, such as smiling, grinning, eye blinking, head nodding, and eyebrow rising give additional information of the speaker's emotional state. The emotional state may be even concluded from facial expression without any sound. Fluent speech is also emphasized and punctuated by facial expressions. With visual information added to synthesized speech it is also possible to increase the intelligibility significantly, especially when the auditory speech is degraded by for example noise, bandwidth filtering, or hearing impairment. The visual information is especially helpful with front phonemes whose articulation we can see, such as labiodentals and bilabials (Beskow et al. 1997). For example, intelligibility between /b/ and /d/ increases signifi- cantly with visual information (Santen et al. 1997). Synthetic face also increases the intelligibility with natural speech. However, the facial gestures and speech must be coherent. Without coherence the intelligibility of speech may be even decreased.
Text-to-speech (TTS) synthesizer produces speech based on the corresponding text input. It has been utilized to provide easier means of communication and to improve accessibility for people with visual impairment to textual information. This language dependent system has been widely developed for various languages with continuous research to improve the quality of the produced speech.
A TTS voice is a computer program that has two major parts: a natural language processing (NLP) which reads the input text and translates it into a phonetic language and a dig- ital signal processing (DSP) that converts the phonetic lan- guage into spoken speech. The input text might be for exam- ple data from a word processor, standard ASCII from e-mail, a mobile text-message, or scanned text from a newspaper. The character string is then preprocessed and analyzed into pho- netic representation which is usually a string of phonemes with some additional information for linguistic representation.
The process of concatenative speech synthesis is cutting and pasting the short segments of speech is selected from a pre- recorded database and joined one after another to pr duce the desired utterances. In theory, the use of real speech as the basis of synthetic speech brings about the potential for very high quality, but in practice there are serious limitations, mainly due to the memory capacity required by such a system. The longer the selected units are, the fewer problematic concatenation points will occur in the synthetic speech, but at the same time the memory requirements increase. Another limitation in Concatenative synthesis is the strong dependency of the output speech on the chosen database. For example, the personality or the affective tone of the speech is hardly controllable. Despite the somewhat featureless nature, Concatenative synthesis is well suited for certain limited
applications [15]. Concatenative synthesis is based on the concatenation or stringing together of segments of recorded speech. Generally, Concatenative synthesis produces the most natural-sounding synthesized speech. It is easier to obtain more natural sound with longer units and it can achieve a high segmental quality. Among these techniques, this paper highlights a diphone concatenation-based synthesis technique in Myanmar text-to-speech research.
The basic idea behind building Myanmar diphone databases is to explicitly list all possible phone-phone transitions in a language. One technique is to use target words embedded carrier sentences to ensure that the diphones are pronounced with acceptable duration and prosody. Speech synthesis unit finds the corresponding pre-recorded sounds from its database and tries to concatenate them smoothly. It uses an algorithm like TD-PSOLA (Time-Domain Pitch Synchronous Overlap and Add) to make a smooth pass in diphone. PSOLA method takes two speech signals. One of these signals ends with a voiced part and the other starts with a voiced part.PSOLA changes the pitch values of these two signals so that pitch values at both sides become equal. The advantage of this technique is to obtain a better output speech when compared to other techniques [1].
The structure of diphone database constructs with Arpabet signs to understand the retrieving phonemes. After retrieving the phonemes, we can then retrieve each individual phoneme from a diphone database and concatenate them together with only 50 phonemes; this would be the most economical choice to save space on embedded devices. Diphones are just pairs of partial phonemes. This might be recovered from the pronouncing dic- tionary by taking into account the 1 or 0 designation applied to vowels concerning stress instead of representing a single pho- neme; a diphone represents the end of one phoneme and the be- ginning of another. This is significant because there is less differ- ence in the middle of a phoneme than there is at the beginning and ending edges. The problem is that it greatly increases the size of the diphone database from around 10496 diphones (114 (22Consonants + 42ExceptionWords + 50Vowels) x 114 (22Consonants + 42ExceptionWords + 50Vowels) – 2500 (50Vowels x50Vowles)) in Myanmar Language. The pair of vowel and vowel is not in phoneme sequence for diphone database. So the number of double vowels subtracts from the total diphone database.
The diphone list will be categorized in different categories [11]: Consonants-Consonants, Consonants-Exception Words, Conso- nants-Vowels, Exception Words-Consonants, Exception Words- Exception Words, Exception Words Vowels, Vowels-Consonants, Vowels-Exception Words, Consonants-Silence, Exception Words- Silence, and Vowels-Silence, Silence-Consonants, Silence- Exception Words and Silence-Vowels pairs.
France Telecom (CNET) develops Pitch Synchronous Overlap and Add method. It allows prerecorded speech samples smoothly concatenated and provides good controlling for pitch and duration. Time-domain version, TD-PSOLA, is the most commonly used due to its computational efficiency. The basic algorithm consists of three steps:
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1516
ISSN 2229-5518
1. original speech signal is divided into separate short analysis signal
2. the modification of each analysis signal to synthesis signal and
3. the synthesis step where these segments are recom- bined by means of overlap-adding [15].
The purpose of TD-PSOLA (Time-Domain) is to modify the pitch or timing of a signal as shown in figure7. The process of the TD-PSOLA algorithm is to find the pitch points of the sig- nal and then apply the hamming window centered of the pitch points and extending to the next and previous pitch point. If the speeches want to slow down, the system defines the frame to double. If the speeches want to speed up, the system re- moves the frames in the signal.
Fig.7. TD-PSOLA Algorithm
TD-PSOLA requires an exact marking of pitch points in a time domain signal. Pitch marking any part within a pitch period is okay as long as the algorithm marks the same point for every frame. The most common marking point is the in- stant of glottal closure, which identifies a quick time domain descent. The algorithm creates an array of sample numbers comprise an analysis epoch sequence P = {p1, p2… pn} and it estimates pitch period distance = (pk - pk+1)/2 to get the mid- point of pitch marking as shown in Table 9.
TABLE 9
DEFINING THE PITCH MARKS
This paper gives the results for the diphone-concatenation
with TD-PSOLA method. This system is tested with the 200
Myanmar sentences and this sentence structure is very com-
plex. The Myanmar diphone database stores over 5000 di-
phones for these sentences. Firstly, this system accepts the
segmented Myanmar sentence and then it can produce the
phonetic sequence with the pairs of consonants and vowels by
using Myanmar phonetic dictionary in grapheme-to-phoneme
stage [4]. And then this system checks the phonetic sequence
to get the prosodic features with phonological rules. Finally, it
produces the high quality speech by applying the Myanmar
diphone database with concatenation method that uses TD-
PSOLA algorithm.
The experimental results of diphone-concatenation speech
synthesis can be calculated with precision, recall and f-
measure. The results for 14 types of diphone pairs according
to the total number of 7837 diphone pairs for 350 sentences is
shown in Table10.
TABLE 10
EXPERIMENTAL RESULTS FOR DIPHONE-CONCATENATION
Diphones-Pairs | Recall | Precision | F-Measure |
C-C | 99% | 99% | 99% |
C-Ex | 97.5% | 97.5% | 97.5% |
C-V | 97% | 97% | 97% |
Ex-C | 100% | 100% | 100% |
Ex-Ex | 90% | 90% | 90% |
Ex-V | 94% | 94% | 94% |
V-C | 100% | 100% | 100% |
V-Ex | 92% | 92% | 92% |
C-S | 100% | 100% | 100% |
Ex-S | 98% | 98% | 98% |
V-S | 95% | 95% | 95% |
S-C | 100% | 100% | 100% |
S-Ex | 90% | 90% | 90% |
S-V | 100% | 100% | 100% |
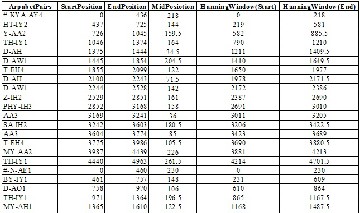
The original waveforms without TD-PSOLA method and the length is 1.206s for first 4 words, “#-KYA-AY4-HT-IY2-Y-AA2- TH-IY1”. Table11 gives the data for the overlapping time ac- cording to the pitch marks with 0.03s of the waveforms of the voices. This table shows the 22 diphone pairs for 20 words Myanmar sentence. The diphone-concatenation pairs for this sentence have the 20 pairs for speech synthesis.
TABLE 11
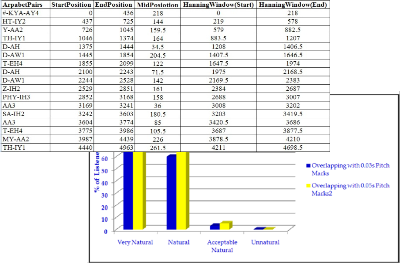
DEFINING THE PITCH MARKS WITH 0.03S
The waveforms
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1517
ISSN 2229-5518
smooth between one joint of waveform and another by using TD-PSOLA method for Myanmar language. The quality of speech is more speed and smooth by are overlapping each to each with 0.03s than original speech waveforms. The total length of overlapping speech waveforms is shorter than origi- nal waveforms without any method. The length of overlap- ping waveforms reduces 0.05s from 1.206s. The next table 12 shows the overlapping of pitch marks with 0.05s between one joint and other joints with 0.05s of waveforms of the voice for
20 words of Myanmar sentence. The hanning window calcu- lates with the overlap of 0.05s pitch marks in each diphone label. The values of the start of hanning window and the end of hanning windows are changed according to the overlap- ping pitch marks values. The sound quality is better than the overlapping pitch marks 0.03ms.
TABLE 12
DEFINING THE PITCH MARKS WITH 0.05S
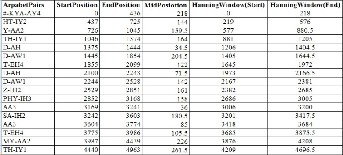
The quality of speech is more speed and smooth by are overlapping each to each with 0.05s than original speech waveforms and 0.03s pitch marks overlapping. The total length of overlapping speech waveforms is shorter than origi- nal waveforms without any method. The length of overlap- ping waveforms reduces 0.12s from 1.206s.
Testing the naturalness and speed of the Myanmar speech contains 12 female people between the ages 16 to 40. The test can be divided into two parts with 20 pairs of words of con- fusability. The first part contains naturalness of the diphone- concatenative speech synthesis. The last part tests the speed of the synthesis system. The participants heard one word at a time and marked on the answering sheet which one of the two words they think is correct.
9.1.1Naturalness
The results of the overlapping with 0.03s pitch marks of lis- tening compared to overlapping with 0.05s pitch marks of lis- tening are shown in figure8 below. The system tested with 20 words complex sentence structure. The listeners or users are regarding the question whether the voice is nice to listen to or not, 90% considered the voice natural, 60% thought that the naturalness of the voice was acceptable and 3 % considered the voice unnatural for pitch marks 0.03s. The users regard
98% considered the voice natural, 70% thought that the natu-
ralness of the voice was acceptable and 5 % considered the voice unnatural for 0.05s pitch marks. The results changed slightly after the second time of listening.
Fig.8. Comparison of Naturalness of the Speech Synthesis
9.1.2Speed
The results of speed of the voices for 0.03s overlapping pitch marks and the speed of 0.05s pitch marks overlapping are shown in figure9. The system tested with 20 words com- plex sentence structure. The questions of speed for the listen- ers or users are asked understood or not the voice or how much of what the voice said the participants understood, 88% of the participants are normal, 73% of the participants fast.
11% neither much nor fast and another 7% understood little fast. The results of 0.05s pitch marks overlapping are 92% of the participants regard normal, 88% of the participants fast.
5% neither much nor fast and another 5% fast a little. The comparison of this speed is shown in figure9.
Fig.9. Comparison of Speed of the Speech Synthesis
This paper gives the results of speech quality for two types of pitch marks overlapping with TD-PSOLA method. The My- anmar diphone database stores over 7000 diphones for 350 sentences of complex structure. This system accepts the seg- mented Myanmar sentence and then it can produce the pho- netic sequence with the pairs of consonants and vowels by using Myanmar phonetic dictionary in grapheme-to-phoneme stage. And then this system checks the phonetic sequence to get the prosodic features with phonological rules. Finally, it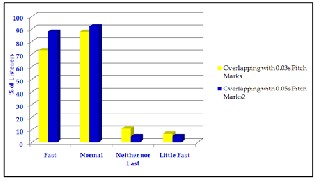
produces the high quality speech by applying the Myanmar diphone database with concatenation method that uses TD- PSOLA algorithm.
This paper shows the speech synthesis results with variety of time domain such as 0.03s and 0.05s pitch marks of hanning windows. The quality of speech with 0.03s is not good when compare with overlapping pitch marks 0.05s. The speed and naturalness of speech for 0.05s is better then the overlapping pitches mark 0.03s in this paper.
This system can be processed by five phonological rules for changing to unvoiced to voiced pronunciations. Emotional state of speech can be extended as one of the research of text- to-speech synthesis.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 6, June-2013 1518
ISSN 2229-5518
I wish to express my deep gratitude and sincere apprecia- tion to all persons who contributed towards the success of my research. It was a great chance to opportunity to study Myan- mar text-to-speech research in one of the most famous re- search in the world. I would like to respectfully thank and appreciate Dr. Mie Mie Thet Thwin, Rector of the University of Computer Studies, Mandalay (UCSM), for her precious ad- vice, patience and encouragement during the preparation of my research. I am grateful to my supervisor, Dr. Aye Thida, an Associate Professor of Research and Development Department (1) at University of Computer Studies, Mandalay (UCSM), and Myanmar, one of the leaders of Natural Language Processing Project for having me helped during the preparation of my research. She was, I am also deeply thankful to Dr. Aye Thida, for her advising from the point of view of natural language processing. I also take this opportunity to thank all our teach- ers of the University of Computer Studies, Mandalay (UCSM), for their teaching and guidance during my research life.
I especially thank my parents, my sisters and all my friends for their encouragement, help, kindness, providing many useful suggestions and giving me their precious time give to me during the preparation of my research.
[1] A. Nur Aziza, H.Rose Maulidiyatul, T.Teresa Vania and N.Anto Satriyo,” Evaluation of Text-to-Speech Synthesizer for Indonesian Language Using Semantically Unpredictable Sentences Test: In- doTTS, eSpeak, and Google Translate TTS”, Proc. of International Conference on Advanced Computer Science & Information Systems,
2011.
[2] Richard Sproa,” Multilingual Text Analysis for Text-to-Speech Syn- thesis”.
[3] Abdelkader Chabchoub and Adnan Cherif,” High Quality Arabic Concatenative Speech Synthesis”, Signal & Image Processing: An In- ternational Journal (SIPIJ) Vol.2, No.4, and December 2011.
[4] Pedro M. Carvalho, Luís C. Oliveira, Isabel M. Trancoso, M. Céu Viana, “CONCATENATIVE SPEECH SYNTHESIS FOR EUROPEAN PORTUGUESE”,
[5] Othman O. Khalifa, Zakiah Hanim Ahmad, and Teddy Surya Gun- awan, “SMaTTS: Standard Malay Text to Speech System”, Interna- tional Journal of Electrical and Computer Engineering 2:4 2007.
[6] W.John Hutchins, “MACHINE TRANSLATION: A BRIEF HISTO- RY”, Concise history of the language sciences: from the Sumerians to the cognitivists. Edited by E.F.K.Koerner and R.E.Asher. Oxford: Per- gamon Press, 1995. Pages 431-445.
[7] Khin Thandar Nwet, Khin Mar Soe and Nilar Thein, “Word Align- ment System Based on Hybried Approach for Myanmar-English Ma- chine Translation”,
[8] Dr. Thein Tun, “Acoustic Phonetics and the Phonology of the Myan- mar Language”, School of Human Communication Sciences, La Trobe University, Melbourne, Australia, 2007.
[9] D.J. RAVI Research Scholar, “Kannada Text to Speech Synthesis Sys- tems: Emotion Analysis”, JSS Research Foundation, S.J College of Engg, Mysore-06, 2010.
[10] Ei Phyu Phyu Soe, “Grapheme-to-Phoneme Conversion for Myanmar Language”, The 11th International Conference on Computer Applica- tions (ICCA 2013).
[11] “Phoneme”, http://en.wikipedia.org/w/index.php, April 2012.
[12] Ei Phyu Phyu Soe, “Prosodic Analysis with Phonological Rules for
Myanmar Text-to-Speech System”, AICT 2013.
[13] Tractament Digital de la Parla, “Introduction to Speech Processing”. [14] Haye s, Bruce (2009). “Introductory Phonology.” Blackwell Textbooks
in Linguistics. Wiley-Blackwell. ISBN 978-1-4051-8411-3.
[15] S. Lemmetty, “Review of Speech Synthesis Technology”, Master’s The-
sis, Helsinki University of Technology, 1999.
[16] Zin Maung Maung, Yoshiki Mikami, “A Rule-based Segmentation for
Myanmar Text”, Nagaoka University Technology, 2007.
IJSER © 2013 http://www.ijser.org